Catalog Cleaning With Pandas
Background
This code will mostly be useful for those whose libraries use Innovative. Innovative data has a lot of quirks that we have to deal with. However, even if your library uses something else for its Integrated Library System, this process will hopefully spark some new ideas on how to not only clean your data, but also extract data for analysis, including transit data and checkin/out data.
Our Data
Only some of this data will be used to find errors. Things like "total checkouts" will be exported to a "Clean Data" file that can then be used to analyze the collection.
| Column Header | Data Type | Example Data |
|---|---|---|
| Bibliographic Record Number | str | b10005377 |
| Item Record Number | str | i10018578 |
| Barcode | str (due to dirty data in the barcode field) | 31189005440932 |
| Title | str | America and I : short stories by American Jewish women writers / edited and with an introduction by Joyce Antler. |
| Author | str | Adler, David A. |
| Call Number | str | FICTION SHORT STORIES America |
| ICode1 (SCAT) | int | 106 |
| ICode2 | str | - |
| IType | int | 0 |
| Location | str | cama |
| Status | str | "- " (note whitespace) |
| Due Date | str | 11-20-2020 OR " - - " (note whitespace) |
| Item Message | str | Thu Nov 12 2020 03:35PM: IN TRANSIT from ca8circ to ca5a |
| Material Type | str | "a " (note whitespace) |
| Language | str | eng |
| Item Created Date | str | 04-01-2003 |
| Publication Info. | str | Boston : Beacon Press, c1990. |
| Price | str | $0.00 |
| Checkout Date | str | 10-30-2020 15:38 |
| Checkout Location | int | 811 |
| Last Checkout Date | str | 01-28-2020 14:07 |
| Last Checkin Date | str | 03-10-2020 14:07 |
| Checkin Location | int | 181 |
| Total Number of Checkouts | int | 77 |
| Last Year Circs | int | 2 |
| Year-To-Date Circs | int | 1 |
| Number of Renewals | int | 0 |
| Total Renewals | int | 3 |
Our Code
I will only post snippets of code here because it is so long, but please feel free to view the whole script on my github.
Import libraries.
import pandas as pd
import numpy as np
import re
import datetime
Read in CSV and rename columns to something more understandable by humans.
dfItems = pd.read_csv('ItemsFullDataMessage.txt', sep='^', encoding='utf8', dtype={'RECORD #(BIBLIO)': str, ...
dfItems.rename(columns={"RECORD #(BIBLIO)": "BibRecord", ...
Prepare our lists.
CallNumberList = dfItems['CallNumber'].tolist()
realSCAT = dfItems['SCAT'].tolist()
realICode2 = dfItems['ICode2'].tolist()
realIType = dfItems['IType'].tolist()
realLoc = dfItems['Location'].tolist()
realLoc = [w.rstrip() for w in realLoc]
dfItems['Location'] = realLoc
realMatType = dfItems['MatType'].tolist()
realMatType = [m.rstrip() for m in realMatType]
dfItems['MatType'] = realMatType
realLang = dfItems['Language'].tolist()
realCreatedDateList = dfItems['ItemCreatedDate'].tolist()
realPubList = dfItems['PubInfo'].tolist()
realMessage = dfItems['Message'].tolist()
realStatus = dfItems['Status'].tolist()
realStatus = [a.rstrip() for a in realStatus]
dfItems['Status'] = realStatus
realDueDate = dfItems['DueDate'].tolist()
Clean up the prices.
dfItems['Price'] = dfItems['Price'].str.replace('$', '').astype(float)
Quirk #1: If the item is checked out, the "status" column has the same status as if the item were available. We need to use the "due date" column to see if an item is really checked out.
newStatus = []
for z in range(len(realStatus)):
if realStatus[z] == "-" and realDueDate[z] == " - - ":
newStatus.append("-")
elif realStatus[z] == "-":
newStatus.append("c")
else:
newStatus.append(realStatus[z])
dfItems['Status'] = newStatus
Get the publication year of the item (this impacts where the item's location and itype). Quirk #2: You can export two different "publication years" from Sierra, our ILS. One is actually the left-most year in the "publication info" field, and the other is the right-most one. There is no guarantee that either will be correct. This code just finds the most recent date in the "publication info" field and sets that as the pub year. Note: remember to change the date to the current year (sometimes people accidentally enter future dates. We don't want these.)
pubYearList = []
yearRegEx = re.compile("\d{4}")
for p in realPubList:
if yearRegEx.search(str(p)):
result = [e for e in re.split("[^\d\d\d\d]", p) if e != '']
if len(str(max(map(int, result)))) == 8:
pubYearList.append(str(max(map(int, result)))[0:4])
elif max(map(int, result)) >= 2022:
pubYearList.append("Check")
else:
pubYearList.append(max(map(int, result)))
else:
pubYearList.append("")
dfItems['PubYear'] = pubYearList
Mark items NEW or OLD (again, determines the item's location and itype). Must also change the dates here.
newList = []
for d in range(len(realCreatedDateList)):
dateList = realCreatedDateList[d].split("-")
if (pubYearList[d] == 'Check' or pubYearList[d] == '') and ((int(dateList[2]) == 2019 and int(dateList[0]) >= 10) or int(dateList[2]) == 2020):
newList.append("Check")
elif (pubYearList[d] == 'Check' or pubYearList[d] == '') and ((int(dateList[2]) == 2019 and int(dateList[0]) <= 9) or int(dateList[2]) <= 2018):
newList.append("Old")
elif ((int(dateList[2]) == 2019 and int(dateList[0]) >= 10) and int(pubYearList[d]) == 2019) or int(pubYearList[d]) == 2020:
newList.append("New")
elif ((int(dateList[2]) == 2020 and int(dateList[0]) <= 2) and int(pubYearList[d]) == 2019):
newList.append("New")
else:
newList.append("Old")
dfItems['NewBooks'] = newList
Make regular expressions that will match call numbers. This is to check the rest of the coding associated with the call number to make sure it all matches. If it doesn't match, the item is potentially has the wrong call number. If the call number doesn't match the spine label, people will be looking for the item in the wrong location.
pat000_019 = re.compile("^(\[Express\]\s)?(\[Black\sStudies\]\s)?0(0|1)\d.*\s[\w,'\s\-]+$")
Check the call numbers against the regular expressions and return the expected ICode1, IType, and Material Type.
LOOKUPS = [
[pat000_019, 1, '0 or 4', 'a'],
...
[patUnknown, 'Unknown', 'Unknown', 'Unknown']
]
def lookup(s, lookups):
for pattern, SCAT, IType, Mat in lookups:
if re.search(pattern, s):
return [SCAT, IType, Mat]
return None
suggestedSCAT = []
suggestedIType = []
suggestedMat = []
for x in CallNumberList:
if re.match(patNonfiction, str(x)):
suggestedSCAT.append(re.search(patNonfiction, str(x)).group(3))
suggestedIType.append('0 or 4')
suggestedMat.append('a')
else :
lookupList = lookup(str(x), LOOKUPS)
suggestedSCAT.append(lookupList[0])
suggestedIType.append(lookupList[1])
suggestedMat.append(lookupList[2])
dfItems['SuggestedSCAT'] = suggestedSCAT
dfItems['SuggestedIType'] = suggestedIType
dfItems['SuggestedMat'] = suggestedMat
Check barcodes for bad data. The barcode field is a variable field, so sometimes people accidentally enter other things in there.
dfItems['BarcodeCheck'] = np.where(dfItems.Barcode.str.match(patBarcode), "Good", "Bad")
Find errors in the coding and call numbers. This is done by comparing the expected codes that we found above, to the codes actually in the catalog.
SCATcomp = []
for i in range(len(suggestedSCAT)):
try:
if suggestedSCAT[i] == 'Unknown':
SCATcomp.append('Bad')
elif suggestedSCAT[i] == '81 or 109' and (realSCAT[i] == 81 or realSCAT[i] == 109):
SCATcomp.append('Good')
elif suggestedSCAT[i] == '91 or 114' and (realSCAT[i] == 91 or realSCAT[i] == 114):
SCATcomp.append('Good')
elif suggestedSCAT[i] == '78 or 116' and (realSCAT[i] == 78 or realSCAT[i] == 116):
SCATcomp.append('Good')
elif suggestedSCAT[i] == '133 or 140' and (realSCAT[i] == 133 or realSCAT[i] == 140):
SCATcomp.append('Good')
elif suggestedSCAT[i] == '165 or 185' and (realSCAT[i] == 165 or realSCAT[i] == 185):
SCATcomp.append('Good')
elif suggestedSCAT[i] == '265 or 140' and (realSCAT[i] == 265 or realSCAT[i] == 140):
SCATcomp.append('Good')
elif (int(suggestedSCAT[i]) >= 1 and int(suggestedSCAT[i]) <= 99) and (realSCAT[i] == int(suggestedSCAT[i]) or realSCAT[i] == 261):
SCATcomp.append('Good')
elif realSCAT[i] == int(suggestedSCAT[i]):
SCATcomp.append('Good')
else:
SCATcomp.append('Bad')
except:
SCATcomp.append('Bad')
dfItems['SCATcheck'] = SCATcomp
Get bad ITypes.
itypeComp = []
for t in range(len(suggestedIType)):
try:
if suggestedIType[t] == 'Unknown':
itypeComp.append('Bad')
elif (realLoc[t] == 'ca3a' or realLoc[t] == 'ca3al') and realIType[t] == 6:
itypeComp.append('Good')
elif re.match('^\[E.*', str(CallNumberList[t])) and realSCAT[t] == 114 and realIType[t] == 4:
itypeComp.append('Good')
...
elif suggestedIType[t] == realIType[t]:
itypeComp.append('Good')
else:
itypeComp.append('Bad')
except:
itypeComp.append('Bad')
dfItems['ITYPEcheck'] = itypeComp
Check Material Type.
matComp = []
for m in range(len(suggestedMat)):
try:
if suggestedMat[m] == 'Unknown':
matComp.append('Bad')
elif suggestedMat[m] == 'a, 5, k' and (realMatType[m] == 'a' or realMatType[m] == '5' or realMatType[m] == 'k'):
matComp.append('Good')
...
elif suggestedMat[m] == 'a, g, 5' and realMatType[m] == 'a':
matComp.append('Good')
elif str(suggestedMat[m]) == realMatType[m]:
matComp.append('Good')
else:
matComp.append('Bad')
except:
matComp.append('Bad')
dfItems['MATcheck'] = matComp
ICode2 check.
ic2Comp = []
for c in range(len(suggestedMat)):
if (realIType[c] == 6 or realIType[c] == 7) and realICode2[c] != 'n':
ic2Comp.append('Bad')
elif (realIType[c] != 6 and realIType[c] != 7) and realICode2[c] == 'n':
ic2Comp.append('Bad')
elif realICode2[c] == ' ':
ic2Comp.append('Bad')
else:
ic2Comp.append('Good')
dfItems['ICODE2check'] = ic2Comp
Language check.
LangComp = []
for l in range(len(suggestedMat)):
if realSCAT[l] == 131 and realLang[l] != 'por':
LangComp.append('Bad')
elif realSCAT[l] == 132 and realLang[l] != 'spa':
LangComp.append('Bad')
elif realSCAT[l] == 133 and realLang[l] != 'chi':
LangComp.append('Bad')
elif realSCAT[l] == 134 and realLang[l] != 'fre':
LangComp.append('Bad')
elif realSCAT[l] == 135 and realLang[l] != 'hat':
LangComp.append('Bad')
elif realSCAT[l] == 262 and realLang[l] != 'spa':
LangComp.append('Bad')
elif realSCAT[l] == 263 and realLang[l] != 'por':
LangComp.append('Bad')
elif realSCAT[l] == 264 and realLang[l] != 'fre':
LangComp.append('Bad')
elif realSCAT[l] == 265 and realLang[l] != 'chi':
LangComp.append('Bad')
else:
LangComp.append('Good')
dfItems['LANGcheck'] = LangComp
Check locations based on ICode1 (the real one, not the expected one).
locCheckList = []
for s in range(len(suggestedMat)):
try:
if ((realSCAT[s] >= 40 and realSCAT[s] <= 49) or (realSCAT[s] >= 131 and realSCAT[s] <= 135)) and re.match(".*(CDB|DVD|BOP).*", str(CallNumberList[s])) and (realLoc[s] == 'camn' or realLoc[s] == 'ca4n' or realLoc[s] == 'ca5n' or realLoc[s] == 'ca6n' or realLoc[s] == 'ca7n' or realLoc[s] == 'ca8n' or realLoc[s] == 'ca9n'):
locCheckList.append('Good')
elif (realSCAT[s] <= 99 or realSCAT[s] == 101 or realSCAT[s] == 102 or realSCAT[s] == 103 or realSCAT[s] == 106 or realSCAT[s] == 109) and newList[s] == 'New' and (realLoc[s] == 'caman' or realLoc[s] == 'ca3a' or realLoc[s] == 'ca4a' or realLoc[s] == 'ca5a' or realLoc[s] == 'ca6a' or realLoc[s] == 'ca7a' or realLoc[s] == 'ca8a' or realLoc[s] == 'ca9a'):
locCheckList.append('Good')
...
elif realSCAT[s] >= 228 and realLoc[s][3] == 'j':
locCheckList.append('Good')
else:
locCheckList.append('Bad')
except:
locCheckList.append('Bad')
dfItems['LOCcheck'] = locCheckList
Prep transit table. This will essentially let us analyze book traffic (where items are going, why, and how long they take to get there).
transitDateTime = []
transitTo = []
trasitFrom = []
transitHold = []
patTransit = re.compile('(.*;")?(.*):\sIN\sTRANSIT\sfrom\s(\w\w\w).*\sto\s(\w\w\w)(\w)')
for y in realMessage:
if re.match(patTransit, str(y)):
transitDateTime.append(re.search(patTransit, str(y)).group(2))
transitTo.append(re.search(patTransit, str(y)).group(4))
trasitFrom.append(re.search(patTransit, str(y)).group(3))
if re.search(patTransit, str(y)).group(5) == 'z':
transitHold.append("Yes")
else:
transitHold.append("No")
else :
transitDateTime.append("")
transitTo.append("")
trasitFrom.append("")
transitHold.append("")
transitDate = []
transitTime = []
for u in transitDateTime:
if u != '':
datetimeobj = datetime.datetime.strptime(u, '%a %b %d %Y %I:%M%p')
transitDate.append(datetimeobj.date())
transitTime.append(datetimeobj.time())
else:
transitDate.append('')
transitTime.append('')
dfItems['TransitDate'] = transitDate
dfItems['TransitTime'] = transitTime
dfItems['TransitTo'] = transitTo
dfItems['TransitFrom'] = trasitFrom
dfItems['TransitHold'] = transitHold
Write transit table to CSV.
dfTransit = dfItems.loc[((dfItems['Status'] == 't') & (dfItems['BarcodeCheck'] == 'Good') & (dfItems['SCATcheck'] == 'Good') & (dfItems['ITYPEcheck'] == 'Good') & (dfItems['MATcheck'] == 'Good') & (dfItems['ICODE2check'] == 'Good') & (dfItems['LANGcheck'] == 'Good') & (dfItems['LOCcheck'] == 'Good'))]
transitHeader = ["ItemRecord", "TransitDate", "TransitTime", "TransitTo", "TransitFrom", "TransitHold"]
dfTransit.to_csv('outtransit.txt', columns = transitHeader, sep='^', index=False)
Separate clean and dirty data. Use the clean data to get checkin/checkout data.
dfDirty = dfItems.loc[((dfItems['BarcodeCheck'] == 'Bad') | (dfItems['SCATcheck'] == 'Bad') | (dfItems['ITYPEcheck'] == 'Bad') | (dfItems['MATcheck'] == 'Bad') | (dfItems['ICODE2check'] == 'Bad') | (dfItems['LANGcheck'] == 'Bad') | (dfItems['LOCcheck'] == 'Bad'))]
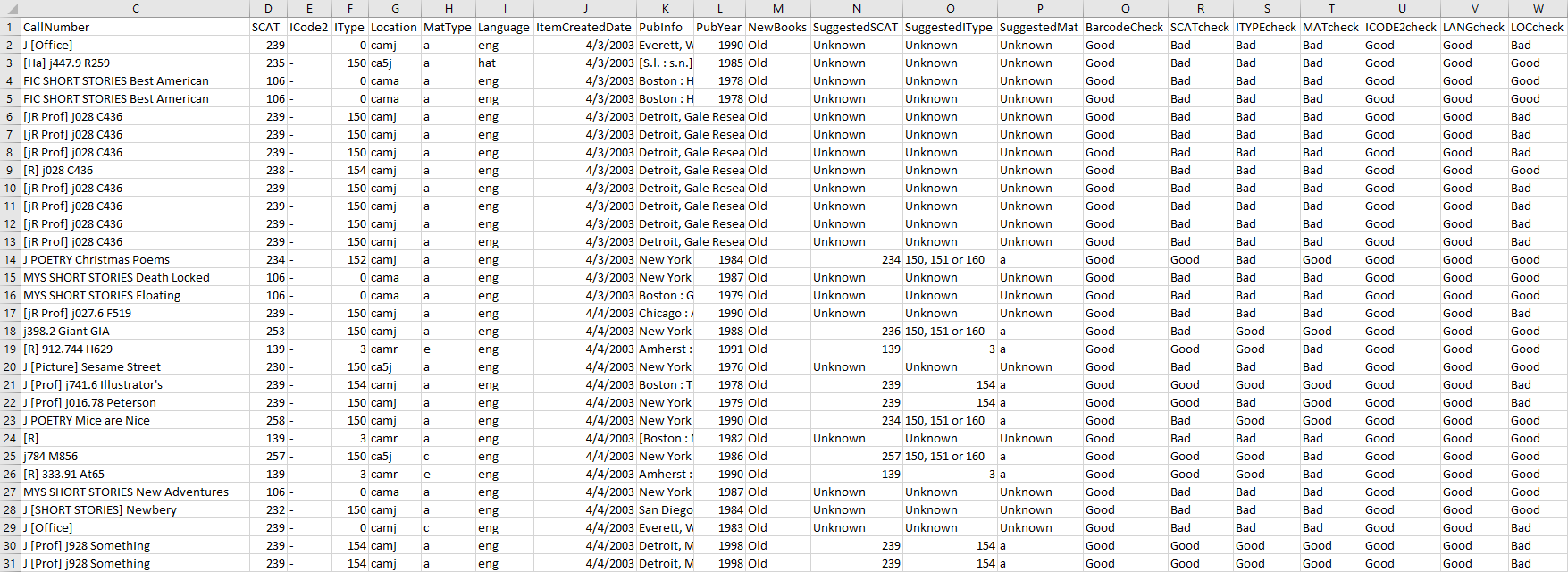
dirtyHeader = ["ItemRecord", "Barcode", "CallNumber", "SCAT", "ICode2", "IType", "Location", "MatType", "Language", "ItemCreatedDate", "PubInfo", "PubYear", "NewBooks", "SuggestedSCAT", "SuggestedIType", "SuggestedMat", "BarcodeCheck", "SCATcheck", "ITYPEcheck", "MATcheck", "ICODE2check", "LANGcheck", "LOCcheck" ]
dfClean = dfItems.loc[((dfItems['BarcodeCheck'] == 'Good') & (dfItems['SCATcheck'] == 'Good') & (dfItems['ITYPEcheck'] == 'Good') & (dfItems['MATcheck'] == 'Good') & (dfItems['ICODE2check'] == 'Good') & (dfItems['LANGcheck'] == 'Good') & (dfItems['LOCcheck'] == 'Good'))]
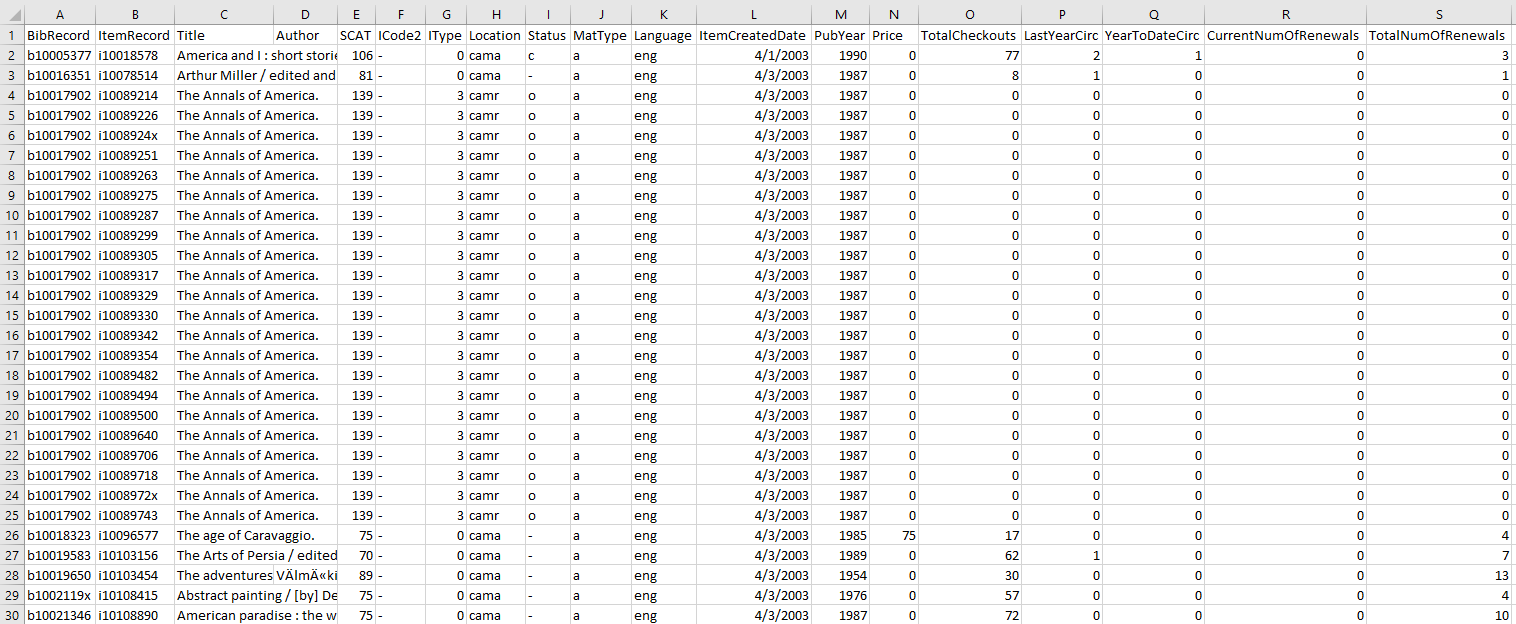
cleanHeader = ["BibRecord", "ItemRecord", "Title", "Author", "SCAT", "ICode2", "IType", "Location", "Status", "MatType", "Language", "ItemCreatedDate", "PubYear", "Price", "TotalCheckouts", "LastYearCirc", "YearToDateCirc", "CurrentNumOfRenewals", "TotalNumOfRenewals"]
cociHeader = ["ItemRecord", "Location", "CheckoutDate", "CheckoutLocation", "LastCheckoutDate", "LastCheckinDate", "CheckinLocation"]
dfClean.to_csv('outcoci.txt', columns = cociHeader, sep='^', index=False)
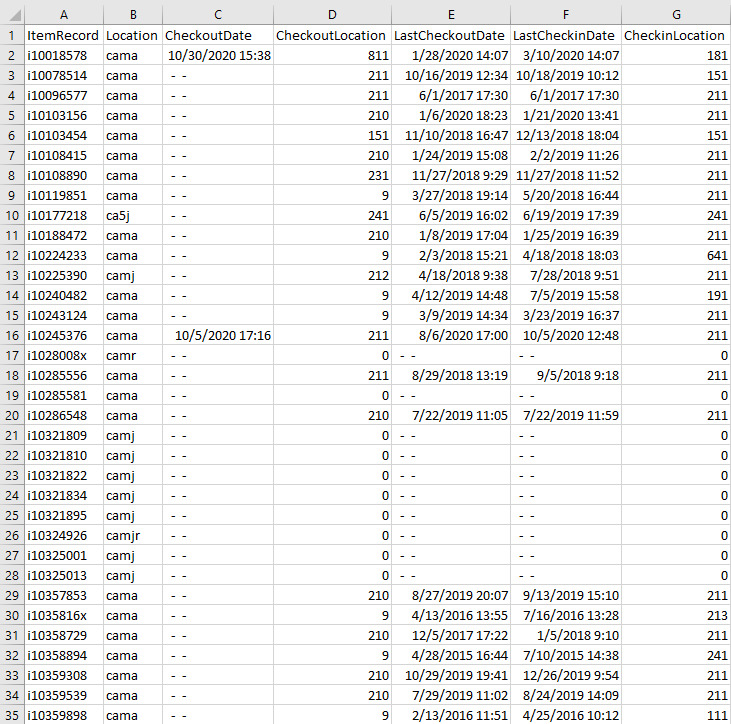
Write dataframes to new documents.
dfDirty.to_csv('outdirty.txt', columns = dirtyHeader, sep='^', index=False)
dfClean.to_csv('outclean.txt', columns = cleanHeader, sep='^', index=False)
Thanks for reading! If you have any comments or questions, feel free to email me at kate@kate-wolfe.com.