Holdshelves and Machine Learning
What are we doing?
I don't know! This is my first attempt at machine learning. I'm following an article called Evaluate Topic Models: Latent Dirichlet Allocation (LDA) Hopefully we will be able to use this to get an idea of what our patrons are requesting. For example, if they are requesting a lot of math and science books, maybe we should buy more, or perhaps there is a particular book that is very popular that we don't have enough of.
Our Data
To do this I've captured a snapshot of what is currently on the holdshelf at the library. It's got the language, material type, and location so that we can properly filter our data. Plus subject headings so we can see what the item or book is about.

Our Code
First we're going to clean the holdshelf data.
Import libraries and read in CSV.
import pandas as pd
holdshelf = pd.read_csv("MLNholds.txt", delimiter='^')
holdshelf.rename(columns={'RECORD #(BIBLIO)':'BibRecord', 'RECORD #(ITEM)':'ItemRecord', 'HOLD(ITEM)':'Holds'}, inplace=True)
Choose which branch's holdshelf we're looking at (I've grabbed data from every library in the network).
import re
pattern = r"PU=(...)"
pickup_location = "ca6" #@param ["ca4", "ca5", "ca6", "ca7", "ca8", "ca9", "cam"]
holdshelf["PickupLoc"] = holdshelf.Holds.str.extract(pattern)
libSubset = holdshelf[~holdshelf['LOCATION'].str.contains(pickup_location)]
libSubset = libSubset[libSubset["PickupLoc"] == pickup_location]
Specify language, material type, and audience (adult, juv, ya).
language = "eng" #@param ["eng", "spa", "chi", "fre"]
mat_type = "book" #@param ["book", "movie", "audiobook", "music"]
audience = "adult" #@param ["adult", "ya", "juv"]
lang = libSubset[libSubset["LANG"] == language]
if audience == "adult":
aud = libSubset[libSubset["I TYPE"] < 100]
elif audience == "ya":
aud = libSubset[(libSubset["I TYPE"] >= 100) & (libSubset["I TYPE"] < 150)]
else:
aud = libSubset[(libSubset["I TYPE"] >= 150) & (libSubset["I TYPE"] < 200)]
bookType = ["a ", "2 ", "f ", "3 ", "c ", "e ", "t "]
movieType = ["5 ", "u ", "g ", "x ", "6 "]
audiobookType = ["4 ", "i ", "z ", "9 "]
musicType = ["j ", "7 ", "8 "]
if mat_type == "book":
mat = libSubset[libSubset["MAT TYPE"].isin(bookType)]
elif mat_type == "movie":
mat = libSubset[libSubset["MAT TYPE"].isin(movieType)]
elif mat_type == "audiobook":
mat = libSubset[libSubset["MAT TYPE"].isin(audiobookType)]
else:
mat = libSubset[libSubset["MAT TYPE"].isin(musicType)]
dfs = [lang, mat, aud]
finalSet = pd.concat([df for df in dfs], axis=1, join='inner').reset_index()
finalSet = finalSet.loc[:,~finalSet.columns.duplicated()].copy()
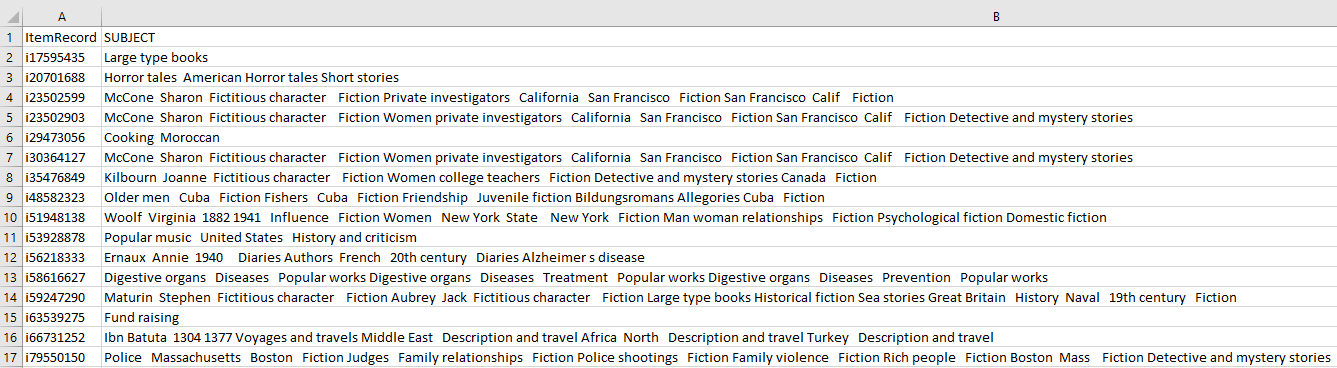
Get a final CSV of our clean data.
subSet = finalSet[['ItemRecord','SUBJECT']]
subSet = subSet.dropna()
p = re.compile(r'[^\w\s]+')
subSet['SUBJECT'] = [p.sub(' ', x) for x in subSet['SUBJECT'].tolist()]
subSet.to_csv('holdshelf.csv', index=False)
Here's where the real fun begins!
Import libraries and read in CSV.
import pandas as pd
import gensim
from gensim.utils import simple_preprocess
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
holdshelf = pd.read_csv("holdshelf.csv")
Remove stop words. Stop words are words that are so common that they don't carry a lot of useful information. These are words like "a," "the," and "is." Actually, I expect very few stopwords to be in this dataset since subject headings are really natural language.
stop_words = stopwords.words('english')
def sent_to_words(sentences):
for sentence in sentences:
# deacc=True removes punctuations
yield(gensim.utils.simple_preprocess(str(sentence), deacc=True))
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc))
if word not in stop_words] for doc in texts]
data = holdshelf.SUBJECT.values.tolist()
data_words = list(sent_to_words(data))
# remove stop words
data_words = remove_stopwords(data_words)
print(data_words[:1][0][:30])
Here we are building bigram and trigram models. N-grams are co-occurring words. They are often used to predict text.
# Build the bigram and trigram models
bigram = gensim.models.Phrases(data_words, min_count=5, threshold=100) # higher threshold fewer phrases.
trigram = gensim.models.Phrases(bigram[data_words], threshold=100)
# Faster way to get a sentence clubbed as a trigram/bigram
bigram_mod = gensim.models.phrases.Phraser(bigram)
trigram_mod = gensim.models.phrases.Phraser(trigram)
Lemmatization normalizes words by removing inflections. For example, "changed" or "changing" to "change."
# Define functions for bigrams, trigrams and lemmatization
def make_bigrams(texts):
return [bigram_mod[doc] for doc in texts]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in texts]
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
"""https://spacy.io/api/annotation"""
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
Do the lemmatization.
import spacy
# Form Bigrams
data_words_bigrams = make_bigrams(data_words)
# Initialize spacy 'en' model, keeping only tagger component (for efficiency)
nlp = spacy.load("en_core_web_sm", disable=['parser', 'ner'])
# Do lemmatization keeping only noun, adj, vb, adv
data_lemmatized = lemmatization(data_words_bigrams, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV'])
print(data_lemmatized[:1])
Term Document Frequency (tf-idf) is really interesting! It's supposed to tell you how important a word is for a given document. The value increases each time a word appears in a document, but decreases if the word appears in many documents, to weed out words that appear often in general.
import gensim.corpora as corpora
# Create Dictionary
id2word = corpora.Dictionary(data_lemmatized)
# Create Corpus
texts = data_lemmatized
# Term Document Frequency
corpus = [id2word.doc2bow(text) for text in texts]
Build LDA model.
lda_model = gensim.models.LdaMulticore(corpus=corpus,
id2word=id2word,
num_topics=10,
random_state=100,
chunksize=100,
passes=10,
per_word_topics=True)
from pprint import pprint
# Print the Keyword in the 10 topics
pprint(lda_model.print_topics())
doc_lda = lda_model[corpus]
Compute coherence score.
from gensim.models import CoherenceModel
coherence_model_lda = CoherenceModel(model=lda_model, texts=data_lemmatized, dictionary=id2word, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score: ', coherence_lda)
Output: Coherence Score: 0.4437542003425629
Supporting function (?)
def compute_coherence_values(corpus, dictionary, k, a, b):
lda_model = gensim.models.LdaMulticore(corpus=corpus,
id2word=dictionary,
num_topics=k,
random_state=100,
chunksize=100,
passes=10,
alpha=a,
eta=b)
coherence_model_lda = CoherenceModel(model=lda_model, texts=data_lemmatized, dictionary=id2word, coherence='c_v')
return coherence_model_lda.get_coherence()
Tuning
This is to help adjust the parameters so we get the best results. It can take a long time. Skip it if you've already tuned.
import numpy as np
import tqdm
grid = {}
grid['Validation_Set'] = {}
# Topics range
min_topics = 2
max_topics = 11
step_size = 1
topics_range = range(min_topics, max_topics, step_size)
# Alpha parameter
alpha = list(np.arange(0.01, 1, 0.3))
alpha.append('symmetric')
alpha.append('asymmetric')
# Beta parameter
beta = list(np.arange(0.01, 1, 0.3))
beta.append('symmetric')
# Validation sets
num_of_docs = len(corpus)
corpus_sets = [# gensim.utils.ClippedCorpus(corpus, num_of_docs*0.25),
# gensim.utils.ClippedCorpus(corpus, num_of_docs*0.5),
gensim.utils.ClippedCorpus(corpus, int(num_of_docs*0.75)),
corpus]
corpus_title = ['75% Corpus', '100% Corpus']
model_results = {'Validation_Set': [],
'Topics': [],
'Alpha': [],
'Beta': [],
'Coherence': []
}
if 1 == 1:
pbar = tqdm.tqdm(total=540)
# iterate through validation corpuses
for i in range(len(corpus_sets)):
# iterate through number of topics
for k in topics_range:
# iterate through alpha values
for a in alpha:
# iterare through beta values
for b in beta:
# get the coherence score for the given parameters
cv = compute_coherence_values(corpus=corpus_sets[i], dictionary=id2word, k=k, a=a, b=b)
# Save the model results
model_results['Validation_Set'].append(corpus_title[i])
model_results['Topics'].append(k)
model_results['Alpha'].append(a)
model_results['Beta'].append(b)
model_results['Coherence'].append(cv)
pbar.update(1)
pd.DataFrame(model_results).to_csv('/content/drive/MyDrive/Holdshelves/lda_tuning_results.csv', index=False)
pbar.close()

Adjustments
Adjust parameters based on tuning results.
lda_model = gensim.models.LdaMulticore(corpus=corpus,
id2word=id2word,
num_topics=3,
random_state=100,
chunksize=100,
passes=10,
alpha=0.01,
eta=0.61)
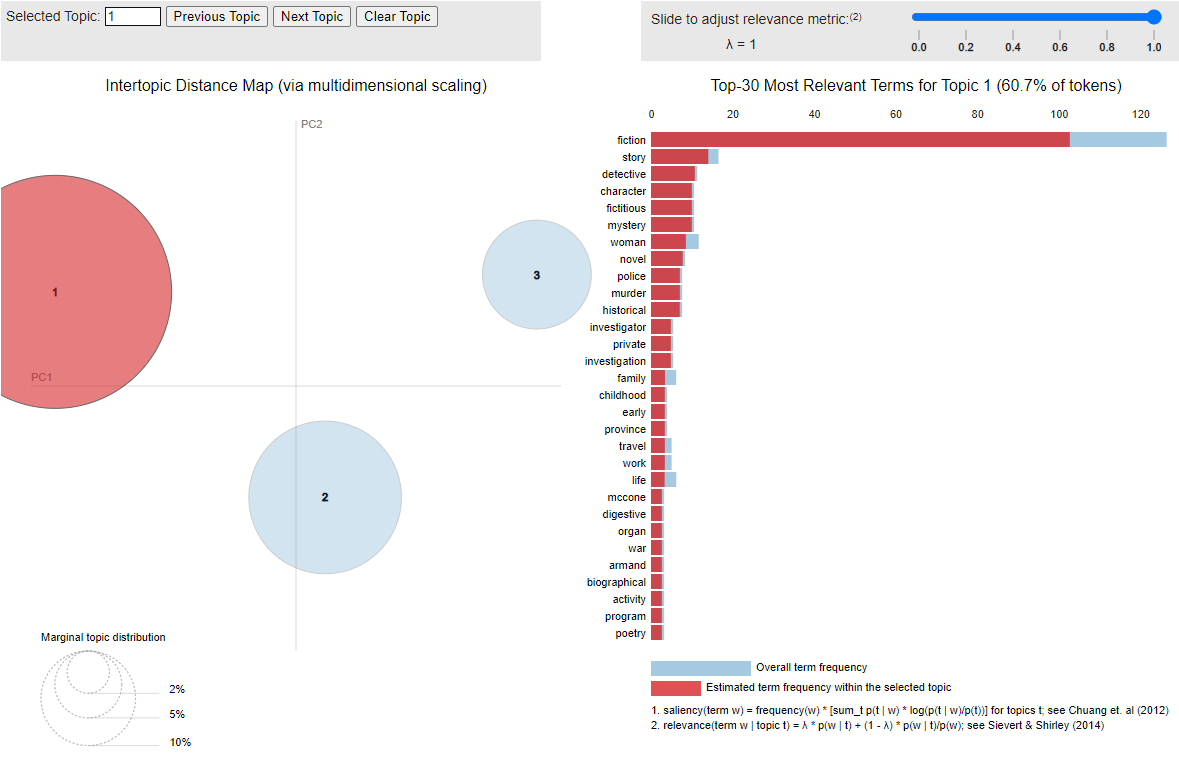
Graph it.
!pip install pyLDAvis
import pyLDAvis.gensim_models
import pickle
import pyLDAvis
# Visualize the topics
pyLDAvis.enable_notebook()
LDAvis_prepared = pyLDAvis.gensim_models.prepare(lda_model, corpus, id2word)
LDAvis_prepared
Thanks for reading! If you have any comments or questions, feel free to email me at kate@kate-wolfe.com.